相信大家一定碰到過,開啟某個網頁,卻顯示一堆像亂碼,如”б?Я?зЪ?Я”、”�????????”?還記得HTTP中的Accept-Charset、Accept-Encoding、Accept-Language、Content-Encoding、Content-Language等訊息頭欄位?這些就是接下來我們要探討的。
目錄:
1.基礎知識
2.常用字符集和字元編碼
2.1. ASCII字符集&編碼
2.2. GBXXXX字符集&編碼
2.3. BIG5字符集&編碼
3.偉大的創想Unicode
3.1.UCS & UNICODE
3.2.UTF-32
3.3.UTF-16
3.4.UTF-8
4.Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language
參考文獻&進一步閱讀
1.基礎知識
計算機中儲存的資訊都是用二進位制數表示的;而我們在螢幕上看到的英文、漢字等字元是二進位制數轉換之後的結果。通俗的說,按照何種規則將字元儲存在計算機中,如’a’用什麼表示,稱為”編碼”;反之,將儲存在計算機中的二進位制數解析顯示出來,稱為”解碼”,如同密碼學中的加密和解密。在解碼過程中,如果使用了錯誤的解碼規則,則導致’a’解析成’b’或者亂碼。
字符集(Charset):是一個系統支援的所有抽象字元的集合。字元是各種文字和符號的總稱,包括各國家文字、標點符號、圖形符號、數字等。
字元編碼(Character Encoding):是一套法則,使用該法則能夠對自然語言的字元的一個集合(如字母表或音節表),與其他東西的一個集合(如號碼或電脈衝)進行配對。即在符號集合與數字系統之間建立對應關係,它是資訊處理的一項基本技術。通常人們用符號集合(一般情況下就是文字)來表達資訊。而以計算機為基礎的資訊處理系統則是利用元件(硬體)不同狀態的組合來儲存和處理資訊的。元件不同狀態的組合能代表數字系統的數字,因此字元編碼就是將符號轉換為計算機可以接受的數字系統的數,稱為數字程式碼。
2.常用字符集和字元編碼
常見字符集名稱:ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。計算機要準確的處理各種字符集文字,需要進行字元編碼,以便計算機能夠識別和儲存各種文字。
2.1. ASCII字符集&編碼
ASCII(American Standard Code for Information Interchange,美國資訊交換標準程式碼)是基於拉丁字母的一套電腦編碼系統。它主要用於顯示現代英語,而其擴充套件版本EASCII則可以勉強顯示其他西歐語言。它是現今最通用的單位元組編碼系統(但是有被Unicode追上的跡象),並等同於國際標準ISO/IEC 646。
ASCII字符集:主要包括控制字元(回車鍵、退格、換行鍵等);可顯示字元(英文大小寫字元、阿拉伯數字和西文符號)。
ASCII編碼:將ASCII字符集轉換為計算機可以接受的數字系統的數的規則。使用7位(bits)表示一個字元,共128字元;但是7位編碼的字符集只能支援128個字元,為了表示更多的歐洲常用字元對ASCII進行了擴充套件,ASCII擴充套件字符集使用8位(bits)表示一個字元,共256字元。ASCII字符集對映到數字編碼規則如下圖所示:
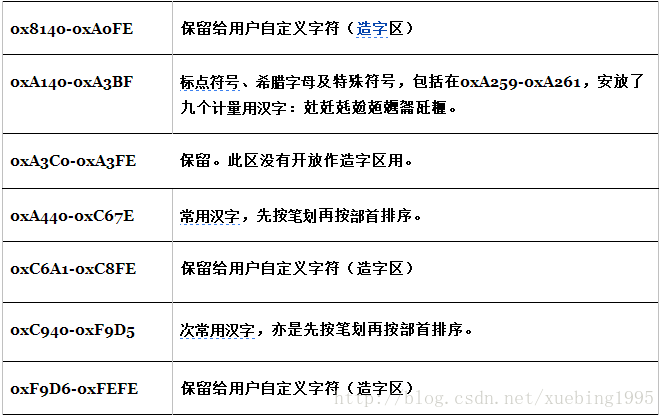 圖1 ASCII編碼表
圖1 ASCII編碼表
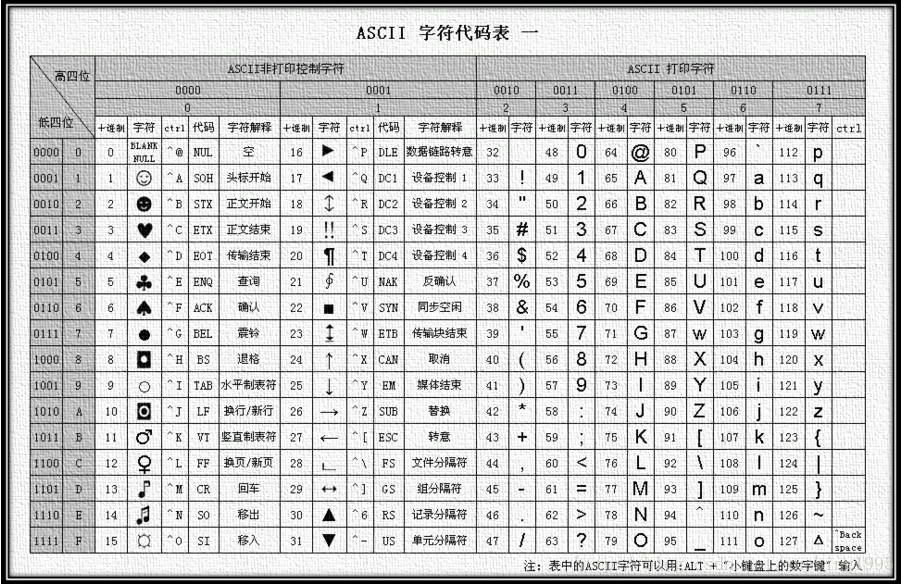 圖2 擴充套件ASCII編碼表
ASCII的最大缺點是隻能顯示26個基本拉丁字母、阿拉伯數目字和英式標點符號,因此只能用於顯示現代美國英語(而且在處理英語當中的外來詞如na?ve、caf?、?lite等等時,所有重音符號都不得不去掉,即使這樣做會違反拼寫規則)。而EASCII雖然解決了部份西歐語言的顯示問題,但對更多其他語言依然無能為力。因此現在的蘋果電腦已經拋棄ASCII而轉用Unicode。
2.2. GBXXXX字符集&編碼
圖2 擴充套件ASCII編碼表
ASCII的最大缺點是隻能顯示26個基本拉丁字母、阿拉伯數目字和英式標點符號,因此只能用於顯示現代美國英語(而且在處理英語當中的外來詞如na?ve、caf?、?lite等等時,所有重音符號都不得不去掉,即使這樣做會違反拼寫規則)。而EASCII雖然解決了部份西歐語言的顯示問題,但對更多其他語言依然無能為力。因此現在的蘋果電腦已經拋棄ASCII而轉用Unicode。
2.2. GBXXXX字符集&編碼
計算機發明之處及後面很長一段時間,只用應用於美國及西方一些發達國家,ASCII能夠很好滿足使用者的需求。但是當天朝也有了計算機之後,為了顯示中文,必須設計一套編碼規則用於將漢字轉換為計算機可以接受的數字系統的數。
天朝專家把那些127號之後的奇異符號們(即EASCII)取消掉,規定:一個小於127的字元的意義與原來相同,但兩個大於127的字元連在一起時,就表示一個漢字,前面的一個位元組(他稱之為高位元組)從0xA1用到 0xF7,後面一個位元組(低位元組)從0xA1到0xFE,這樣我們就可以組合出大約7000多個簡體漢字了。在這些編碼裡,還把數學符號、羅馬希臘的 字母、日文的假名們都編進去了,連在ASCII裡本來就有的數字、標點、字母都統統重新編了兩個位元組長的編碼,這就是常說的”全形”字元,而原來在127號以下的那些就叫”半形”字元了。
上述編碼規則就是GB2312。GB2312或GB2312-80是中國國家標準簡體中文字符集,全稱《資訊交換用漢字編碼字符集·基本集》,又稱GB0,由中國國家標準總局釋出,1981年5月1日實施。GB2312編碼通行於中國大陸;新加坡等地也採用此編碼。中國大陸幾乎所有的中文系統和國際化的軟體都支援GB2312。GB2312的出現,基本滿足了漢字的計算機處理需要,它所收錄的漢字已經覆蓋中國大陸99.75%的使用頻率。對於人名、古漢語等方面出現的罕用字,GB2312不能處理,這導致了後來GBK及GB 18030漢字字符集的出現。下圖是GB2312編碼的開始部分(由於其非常龐大,只列舉開始部分,具體可檢視GB2312簡體中文編碼表):
 圖3 GB2312編碼表的開始部分
由於GB 2312-80只收錄6763個漢字,有不少漢字,如部分在GB 2312-80推出以後才簡化的漢字(如”囉”),部分人名用字(如中國前總理朱鎔基的”鎔”字),臺灣及香港使用的繁體字,日語及朝鮮語漢字等,並未有收錄在內。於是廠商微軟利用GB 2312-80未使用的編碼空間,收錄GB 13000.1-93全部字元制定了GBK編碼。根據微軟資料,GBK是對GB2312-80的擴充套件,也就是CP936字碼表 (Code Page 936)的擴充套件(之前CP936和GB 2312-80一模一樣),最早實現於Windows 95簡體中文版。雖然GBK收錄GB 13000.1-93的全部字元,但編碼方式並不相同。GBK自身並非國家標準,只是曾由國家技術監督局標準化司、電子工業部科技與質量監督司公佈為”技術規範指導性檔案”。原始GB13000一直未被業界採用,後續國家標準GB18030技術上相容GBK而非GB13000。
GB 18030,全稱:國家標準GB 18030-2005《資訊科技 中文編碼字符集》,是中華人民共和國現時最新的內碼字集,是GB 18030-2000《資訊科技 資訊交換用漢字編碼字符集 基本集的擴充》的修訂版。與GB 2312-1980完全相容,與GBK基本相容,支援GB 13000及Unicode的全部統一漢字,共收錄漢字70244個。GB 18030主要有以下特點:
與UTF-8相同,採用多位元組編碼,每個字可以由1個、2個或4個位元組組成。
圖3 GB2312編碼表的開始部分
由於GB 2312-80只收錄6763個漢字,有不少漢字,如部分在GB 2312-80推出以後才簡化的漢字(如”囉”),部分人名用字(如中國前總理朱鎔基的”鎔”字),臺灣及香港使用的繁體字,日語及朝鮮語漢字等,並未有收錄在內。於是廠商微軟利用GB 2312-80未使用的編碼空間,收錄GB 13000.1-93全部字元制定了GBK編碼。根據微軟資料,GBK是對GB2312-80的擴充套件,也就是CP936字碼表 (Code Page 936)的擴充套件(之前CP936和GB 2312-80一模一樣),最早實現於Windows 95簡體中文版。雖然GBK收錄GB 13000.1-93的全部字元,但編碼方式並不相同。GBK自身並非國家標準,只是曾由國家技術監督局標準化司、電子工業部科技與質量監督司公佈為”技術規範指導性檔案”。原始GB13000一直未被業界採用,後續國家標準GB18030技術上相容GBK而非GB13000。
GB 18030,全稱:國家標準GB 18030-2005《資訊科技 中文編碼字符集》,是中華人民共和國現時最新的內碼字集,是GB 18030-2000《資訊科技 資訊交換用漢字編碼字符集 基本集的擴充》的修訂版。與GB 2312-1980完全相容,與GBK基本相容,支援GB 13000及Unicode的全部統一漢字,共收錄漢字70244個。GB 18030主要有以下特點:
與UTF-8相同,採用多位元組編碼,每個字可以由1個、2個或4個位元組組成。
編碼空間龐大,最多可定義161萬個字元。
支援中國國內少數民族的文字,不需要動用造字區。
漢字收錄範圍包含繁體漢字以及日韓漢字

圖4 GB18030編碼總體結構
本規格的初版使中華人民共和國資訊產業部電子工業標準化研究所起草,由國家質量技術監督局於2000年3月17日釋出。現行版本為國家質量監督檢驗總局和中國國家標準化管理委員會於2005年11月8日釋出,2006年5月1日實施。此規格為在中國境內所有軟體產品支援的強制規格。
2.3. BIG5字符集&編碼
Big5,又稱為大五碼或五大碼,是使用繁體中文(正體中文)社群中最常用的電腦漢字字符集標準,共收錄13,060個漢字。中文碼分為內碼及交換碼兩類,Big5屬中文內碼,知名的中文交換碼有CCCII、CNS11643。Big5雖普及於臺灣、香港與澳門等繁體中文通行區,但長期以來並非當地的國家標準,而只是業界標準。倚天中文系統、Windows等主要系統的字符集都是以Big5為基準,但廠商又各自增加不同的造字與造字區,派生成多種不同版本。2003年,Big5被收錄到CNS11643中文標準交換碼的附錄當中,取得了較正式的地位。這個最新版本被稱為Big5-2003。
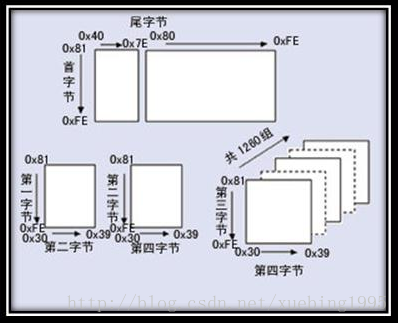
Big5碼是一套雙位元組字符集,使用了雙八碼儲存方法,以兩個位元組來安放一個字。第一個位元組稱為”高位位元組”,第二個位元組稱為”低位位元組”。”高位位元組”使用了0x81-0xFE,”低位位元組”使用了0x40-0x7E,及0xA1-0xFE。在Big5的分割槽中:
3.偉大的創想Unicode
——不得不單獨說Unicode
像天朝一樣,當計算機傳到世界各個國家時,為了適合當地語言和字元,設計和實現類似GB232/GBK/GB18030/BIG5的編碼方案。這樣各搞一套,在本地使用沒有問題,一旦出現在網路中,由於不相容,互相訪問就出現了亂碼現象。
為了解決這個問題,一個偉大的創想產生了——Unicode。Unicode編碼系統為表達任意語言的任意字元而設計。它使用4位元組的數字來表達每個字母、符號,或者表意文字(ideograph)。每個數字代表唯一的至少在某種語言中使用的符號。(並不是所有的數字都用上了,但是總數已經超過了65535,所以2個位元組的數字是不夠用的。)被幾種語言共用的字元通常使用相同的數字來編碼,除非存在一個在理的語源學(etymological)理由使不這樣做。不考慮這種情況的話,每個字元對應一個數字,每個數字對應一個字元。即不存在二義性。不再需要記錄”模式”了。U+0041總是代表’A’,即使這種語言沒有’A’這個字元。
在電腦科學領域中,Unicode(統一碼、萬國碼、單一碼、標準萬國碼)是業界的一種標準,它可以使電腦得以體現世界上數十種文字的系統。Unicode 是基於通用字符集(Universal Character Set)的標準來發展,並且同時也以書本的形式[1]對外發表。Unicode 還不斷在擴增, 每個新版本插入更多新的字元。直至目前為止的第六版,Unicode 就已經包含了超過十萬個字元(在2005年,Unicode 的第十萬個字元被採納且認可成為標準之一)、一組可用以作為視覺參考的程式碼圖表、一套編碼方法與一組標準字元編碼、一套包含了上標字、下標字等字元特性的列舉等。Unicode 組織(The Unicode Consortium)是由一個非營利性的機構所運作,並主導 Unicode 的後續發展,其目標在於:將既有的字元編碼方案以Unicode 編碼方案來加以取代,特別是既有的方案在多語環境下,皆僅有有限的空間以及不相容的問題。
(可以這樣理解:Unicode是字符集,UTF-32/ UTF-16/ UTF-8是三種字元編碼方案。)
3.1.UCS & UNICODE
通用字符集(Universal Character Set,UCS)是由ISO制定的ISO 10646(或稱ISO/IEC 10646)標準所定義的標準字符集。歷史上存在兩個獨立的嘗試創立單一字符集的組織,即國際標準化組織(ISO)和多語言軟體製造商組成的統一碼聯盟。前者開發的 ISO/IEC 10646 專案,後者開發的統一碼專案。因此最初制定了不同的標準。
1991年前後,兩個專案的參與者都認識到,世界不需要兩個不相容的字符集。於是,它們開始合併雙方的工作成果,併為創立一個單一編碼表而協同工作。從Unicode 2.0開始,Unicode採用了與ISO 10646-1相同的字型檔和字碼;ISO也承諾,ISO 10646將不會替超出U+10FFFF的UCS-4編碼賦值,以使得兩者保持一致。兩個專案仍都存在,並獨立地公佈各自的標準。但統一碼聯盟和ISO/IEC JTC1/SC2都同意保持兩者標準的碼錶相容,並緊密地共同調整任何未來的擴充套件。在釋出的時候,Unicode一般都會採用有關字碼最常見的字型,但ISO 10646一般都儘可能採用Century字型。
3.2.UTF-32
上述使用4位元組的數字來表達每個字母、符號,或者表意文字(ideograph),每個數字代表唯一的至少在某種語言中使用的符號的編碼方案,稱為UTF-32。UTF-32又稱UCS-4是一種將Unicode字元編碼的協定,對每個字元都使用4位元組。就空間而言,是非常沒有效率的。
這種方法有其優點,最重要的一點就是可以在常數時間內定位字串裡的第N個字元,因為第N個字元從第4×Nth個位元組開始。雖然每一個碼位使用固定長定的位元組看似方便,它並不如其它Unicode編碼使用得廣泛。
3.3.UTF-16
儘管有Unicode字元非常多,但是實際上大多數人不會用到超過前65535個以外的字元。因此,就有了另外一種Unicode編碼方式,叫做UTF-16(因為16位 = 2位元組)。UTF-16將0–65535範圍內的字元編碼成2個位元組,如果真的需要表達那些很少使用的”星芒層(astral plane)”內超過這65535範圍的Unicode字元,則需要使用一些詭異的技巧來實現。UTF-16編碼最明顯的優點是它在空間效率上比UTF-32高兩倍,因為每個字元只需要2個位元組來儲存(除去65535範圍以外的),而不是UTF-32中的4個位元組。並且,如果我們假設某個字串不包含任何星芒層中的字元,那麼我們依然可以在常數時間內找到其中的第N個字元,直到它不成立為止這總是一個不錯的推斷。其編碼方法是:
如果字元編碼U小於0x10000,也就是十進位制的0到65535之內,則直接使用兩位元組表示;
如果字元編碼U大於0x10000,由於UNICODE編碼範圍最大為0x10FFFF,從0x10000到0x10FFFF之間 共有0xFFFFF個編碼,也就是需要20個bit就可以標示這些編碼。用U’表示從0-0xFFFFF之間的值,將其前 10 bit作為高位和16 bit的數值0xD800進行 邏輯or 操作,將後10 bit作為低位和0xDC00做 邏輯or 操作,這樣組成的 4個byte就構成了U的編碼。
對於UTF-32和UTF-16編碼方式還有一些其他不明顯的缺點。不同的計算機系統會以不同的順序儲存位元組。這意味著字元U+4E2D在UTF-16編碼方式下可能被儲存為4E 2D或者2D 4E,這取決於該系統使用的是大尾端(big-endian)還是小尾端(little-endian)。(對於UTF-32編碼方式,則有更多種可能的位元組排列。)只要文件沒有離開你的計算機,它還是安全的——同一臺電腦上的不同程式使用相同的位元組順序(byte order)。但是當我們需要在系統之間傳輸這個文件的時候,也許在全球資訊網中,我們就需要一種方法來指示當前我們的位元組是怎樣儲存的。不然的話,接收文件的計算機就無法知道這兩個位元組4E 2D表達的到底是U+4E2D還是U+2D4E。
為了解決這個問題,多位元組的Unicode編碼方式定義了一個”位元組順序標記(Byte Order Mark)”,它是一個特殊的非列印字元,你可以把它包含在文件的開頭來指示你所使用的位元組順序。對於UTF-16,位元組順序標記是U+FEFF。如果收到一個以位元組FF FE開頭的UTF-16編碼的文件,你就能確定它的位元組順序是單向的(one way)的了;如果它以FE FF開頭,則可以確定位元組順序反向了。
3.4.UTF-8
UTF-8(8-bit Unicode Transformation Format)是一種針對Unicode的可變長度字元編碼(定長碼),也是一種字首碼。它可以用來表示Unicode標準中的任何字元,且其編碼中的第一個位元組仍與ASCII相容,這使得原來處理ASCII字元的軟體無須或只須做少部份修改,即可繼續使用。因此,它逐漸成為電子郵件、網頁及其他儲存或傳送文字的應用中,優先採用的編碼。網際網路工程工作小組(IETF)要求所有網際網路協議都必須支援UTF-8編碼。
UTF-8使用一至四個位元組為每個字元編碼:
128個US-ASCII字元只需一個位元組編碼(Unicode範圍由U+0000至U+007F)。
帶有附加符號的拉丁文、希臘文、西裡爾字母、亞美尼亞語、希伯來文、阿拉伯文、敘利亞文及它拿字母則需要二個位元組編碼(Unicode範圍由U+0080至U+07FF)。
其他基本多文種平面(BMP)中的字元(這包含了大部分常用字)使用三個位元組編碼。
其他極少使用的Unicode輔助平面的字元使用四位元組編碼。
在處理經常會用到的ASCII字元方面非常有效。在處理擴充套件的拉丁字符集方面也不比UTF-16差。對於中文字元來說,比UTF-32要好。同時,(在這一條上你得相信我,因為我不打算給你展示它的數學原理。)由位操作的天性使然,使用UTF-8不再存在位元組順序的問題了。一份以utf-8編碼的文件在不同的計算機之間是一樣的位元流。
總體來說,在Unicode字串中不可能由碼點數量決定顯示它所需要的長度,或者顯示字串之後在文字緩衝區中游標應該放置的位置;組合字元、變寬字型、不可列印字元和從右至左的文字都是其歸因。所以儘管在UTF-8字串中字元數量與碼點數量的關係比UTF-32更為複雜,在實際中很少會遇到有不同的情形。
優點
UTF-8是ASCII的一個超集。因為一個純ASCII字串也是一個合法的UTF-8字串,所以現存的ASCII文字不需要轉換。為傳統的擴充套件ASCII字符集設計的軟體通常可以不經修改或很少修改就能與UTF-8一起使用。
使用標準的面向位元組的排序例程對UTF-8排序將產生與基於Unicode程式碼點排序相同的結果。(儘管這隻有有限的有用性,因為在任何特定語言或文化下都不太可能有仍可接受的文字排列順序。)
UTF-8和UTF-16都是可擴充套件標記語言文件的標準編碼。所有其它編碼都必須通過顯式或文字宣告來指定。
任何面向位元組的字串搜尋演算法都可以用於UTF-8的資料(只要輸入僅由完整的UTF-8字元組成)。但是,對於包含字元記數的正則表示式或其它結構必須小心。
UTF-8字串可以由一個簡單的演算法可靠地識別出來。就是,一個字串在任何其它編碼中表現為合法的UTF-8的可能性很低,並隨字串長度增長而減小。舉例說,字元值C0,C1,F5至FF從來沒有出現。為了更好的可靠性,可以使用正則表示式來統計非法過長和替代值(可以檢視W3 FAQ: Multilingual Forms上的驗證UTF-8字串的正則表示式)。
缺點
因為每個字元使用不同數量的位元組編碼,所以尋找串中第N個字元是一個O(N)複雜度的操作 — 即,串越長,則需要更多的時間來定位特定的字元。同時,還需要位變換來把字元編碼成位元組,把位元組解碼成字元。
4.Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language
在HTTP中,與字符集和字元編碼相關的訊息頭是Accept-Charset/Content-Type,另外主區區分Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language:
Accept-Charset:瀏覽器申明自己接收的字符集,這就是本文前面介紹的各種字符集和字元編碼,如gb2312,utf-8(通常我們說Charset包括了相應的字元編碼方案);
Accept-Encoding:瀏覽器申明自己接收的編碼方法,通常指定壓縮方法,是否支援壓縮,支援什麼壓縮方法(gzip,deflate),(注意:這不是隻字元編碼);
Accept-Language:瀏覽器申明自己接收的語言。語言跟字符集的區別:中文是語言,中文有多種字符集,比如big5,gb2312,gbk等等;
Content-Type:WEB伺服器告訴瀏覽器自己響應的物件的型別和字符集。例如:Content-Type: text/html; charset=’gb2312’
Content-Encoding:WEB伺服器表明自己使用了什麼壓縮方法(gzip,deflate)壓縮響應中的物件。例如:Content-Encoding:gzip
Content-Language:WEB伺服器告訴瀏覽器自己響應的物件的語言。